December 12, 2020
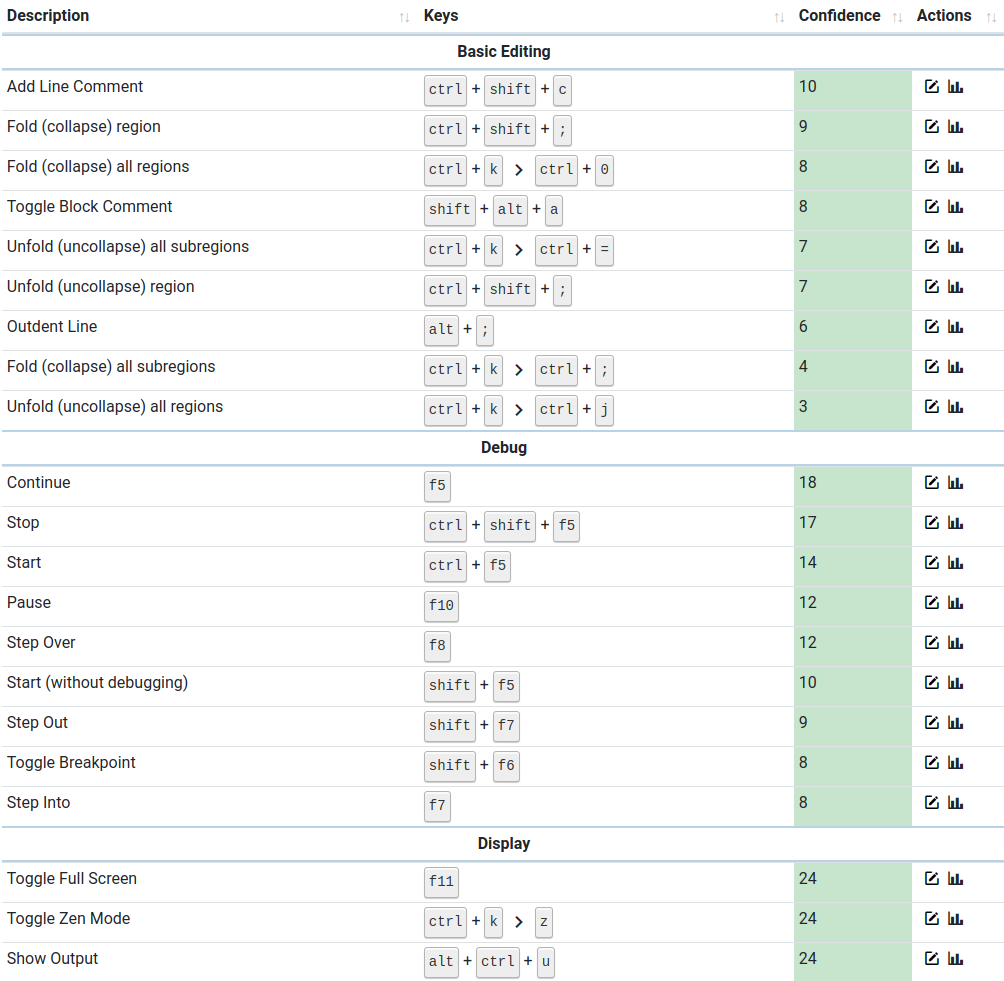
Looking up keyboard shortcuts on the web takes you out of the current context and breaks your workflow. KeyCombiner Desktop shows the current application’s shortcuts in a searchable table, triggered instantly via a system-wide key combination. In contrast to existing tools, it is available for Windows, Linux, and macOS. The lookup also includes all shortcuts and text snippets from your personal KeyCombiner collections, making it a universal cheatsheet.